
2015年负责新一代儿童手表产品的研发,落地智能语音问答,2018年负责360智能音箱的开发,做了360的语音云平台,2019年发布了边缘计算的产品360家庭安全大脑,做了视频的边缘计算。2021年开始在摄像机上力主研发端边云融合的推理框架AI LAB,几年时间从语音到图像,做了很多项目。
我一直有坚定的AI信仰,也在身体力行的推动AI的落地,然而在公司内部想推动达成共识并不容易,经常被问到AI有啥用,因此在2021年底,在360 IoT推进面向安防的场景化视频AI战略的分享,目的是帮助管理层在内的人员了解AI相关的基础知识,推进AI的战略落地。
分成多个章节分别整理,请参考:AI 系列分享
本篇是第四部分,主要分析行业内AI公司的实际情况,推导出360 IoT的AI战略基础,以及接下来的具体做法。
AI战略分析
为什么现在的AI公司做的都不好?
普遍长期大额亏损
这个好不好,不是从产品技术层面,更多是从财务数据、市场表现层面。从财务数据看,AI公司收入和估值不相称,普遍巨额亏损,确实做的不好!

商汤、第四范式数据取自经调整亏损净额;其他公司数据取自扣除非经常性损益后归属于母公司所有者的净利润,均为亏损。
多轮大额融资,快速扩张
多数公司均经过10轮左右的大额融资,包含国内外顶尖投资方,其中商汤历史总融资金额为52亿美元(约336亿人民币),旷视 13亿美金,云从累计超53亿人民币,依图累计融资超30亿。
随着融资团队规模快速扩张,但是对应的收入却没有对应增长,导致持续亏损。
AI四小龙在融资方式、扩张路径和最后的财务结果,表现出了较大的相似性。

业务范围覆盖广
几家公司的业务范围都非常广,智慧城市、智慧校园、智能驾驶、物流、仓储等都有涉及。我参观了旷视的展厅最大的感受不是AI的强大,而是做的业务真是太多了,多确不挣钱,没有成长性、也缺乏在垂直场景的壁垒和竞争力。
以体量较大的商汤为例:

从营收构成来看,大头在指挥商业、智慧城市,但是整体规模相比传统的安防集成商又太小,关建还是高投入、高亏损。

再看一个体量较小的格灵深瞳:

虽然体量较小,但是也是智慧城市、金融、交通、商业全覆盖。而且如果更细致的拆分收入构成变化,也能够发现很多场景并没有核心壁垒,整体波动大。一两个项目就能够拉动整体营收。

而且为了拉升营收,也方便行业应用平台更好的落地,硬件占比逐年提高,除了自有品牌的硬件产品之外,还有大量集成三方的硬件产品。

算法通用,场景不通用,业务不通用

深度学习算法最大的特点和优势就是方法的通用性,但是不同的场景数据不通、业务逻辑不通,单纯拿一个通用的方法去做项目,都面临较多的定制化开发和交付的问题。很多公司在细分行业没有深入积累,接项目有一定的随机性,感觉什么都能做,却又什么都做不好。感觉多少都有点产品能搭上,却又什么都没办法低成本交付。整体就陷入了一个低效的死循环。
这种死循环就导致,看似商机很多,业务越铺越广、项目越做越多,但是边际成本没有降低,整体亏损越来越大。
AI软硬件一体化是行业大趋势
以旷视为例,对旷视收入的软硬件金额进行拆解。

AI只是一个工具,独立成为一个商业化的产品难度太大,必须依附于对应的场景,所以更多是现有软件的能力增强或者依附于具体的硬件,加上很多B端、G端项目中,对实物硬件认可的价值度更高,软硬件一体化更容易集成落地,也更容易降低交付的边际成本。AI四小龙在内的多数AI公司不可避免都走向了软硬一体化。
战略路径选择
传统AI公司-算法 场景 数据

包括AI小龙在内的AI公司有算法但是没有落地场景和数据,收入瓶颈较大,主要聚焦在城市安防等大B场景,且目前逐步集成商化、设备商化。
360 IoT的AI战略路径:数据 场景 算法

我们有设备(摄像机日活400万以上),有数据(每天2亿张以上图片识别调用),有场景,在基础算法框架开源、常用模型开源的情况下,AI可以成为我们的核心竞争力!
360 AIOT的战略分析与实现路径
已经具备主要的人脸、人形、物体识别能力
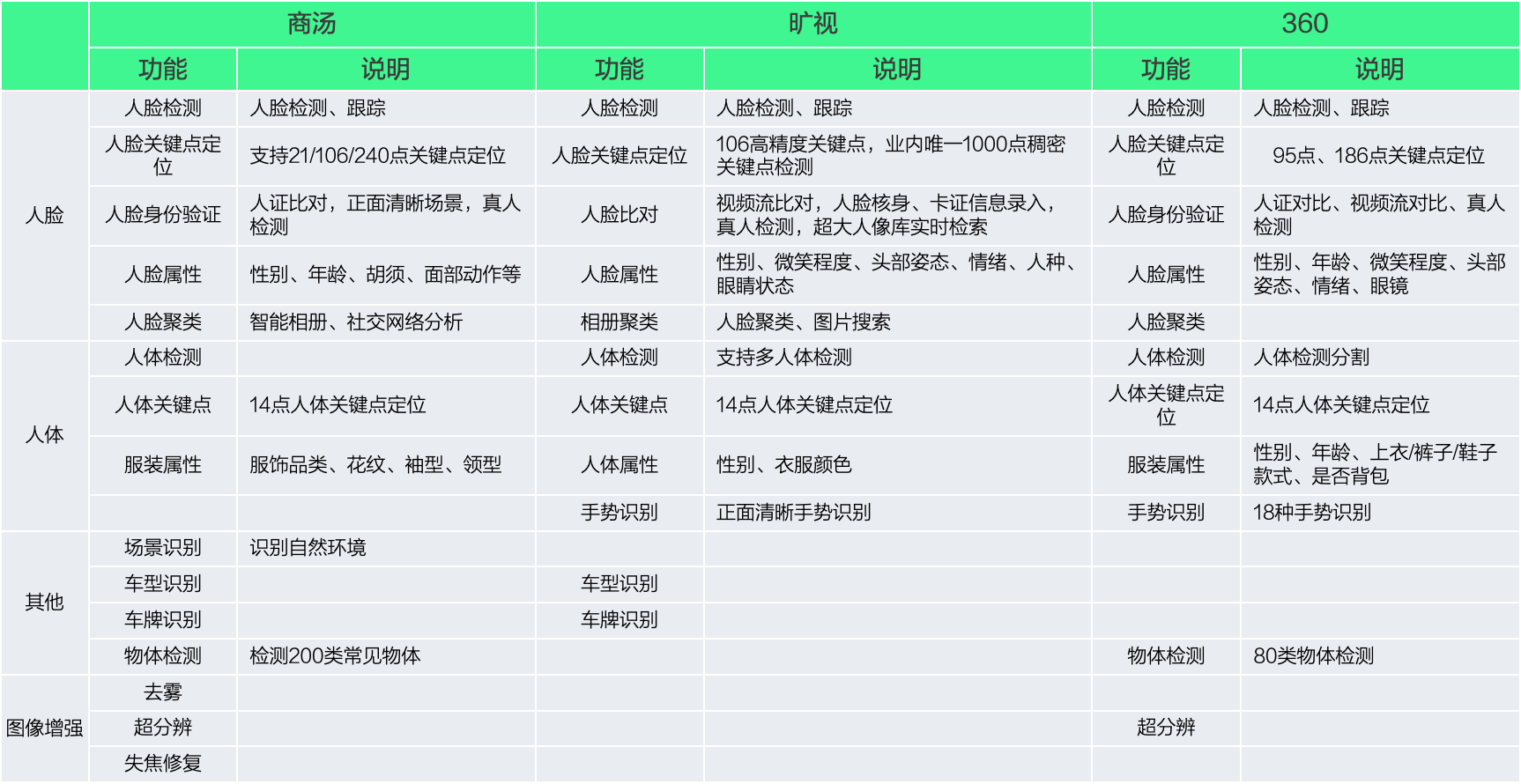
数据的场景针对性是算法最终表现的核心

公司在核心的人脸、人形应用上有基础,在测试结果上优于竞品公司的开放平台服务,使用公司基础服务能够降低成本,提升应用设计的灵活性
人脸、人形是视频结构化的基础服务,如果在云端,则调用次数较多成本较高,针对边缘计算场景,一旦使用第三方的服务,则模型等相对固定,不利于后续做应用层逻辑。
从后续服务拓展和成本角度考虑,在核心的基础服务上,需要基于公司自有的算法做优化。
积极与商汤、旷视等公司合作,在长尾和增值服务上,调用第三方服务
部分公司有些差异化的服务,如情绪、表情识别,可疑人员库等,针对这部分服务,以云端分发的方式调用第三方服务,我们在自有人脸人形服务的基础上做服务分发。
已经对比测试商汤、旷视的算法,云从、澎思、神目等相关算法正在获取中。
持续运营迭代,解决漏报、误报问题是核心,提升AI算法在通用安防场景的可用性

场景不一致,安防场景的模型需要针对性优化
通过对比商汤的SDK发现,部分自有算法能够检出的场景商汤无法检出实际应用中容易造成漏报。
实际应用中,基础的人脸、人形检测不同的训练数据差异较大,需要根据对应场景的数据深度迭代优化相匹配的模型。
环境干扰造成的误报严重,需要叠加场景规则进一步进行事件分级避免对用户造成干扰
树木阴影晃动、夜晚蚊虫干扰容易造成人形的误报,如果不叠加任何事件规则直接就提醒用户容易造成干扰。
针对场景叠加逻辑规则进行事件分级,降低对用户的干扰。
2019年的家庭大脑产品已经做了很多有效的探索

边缘AI调度
将研究院的模型移植到对应的嵌入式平台,做好模型的优化、调试、调度。
也能够灵活调度商汤、旷视等第三方的AI模型,通过分发覆盖更多的长尾场景。
边缘规则引擎
将AI模型识别出来的事件类型,通过特定的场景规则来进行识别分类,如人体移动进一步识别为徘徊、逗留。
边缘规则包含用户的规则、设备的规则、场景的规则。
边云融合的场景引擎
云端能够融合边缘端的识别结果,对可能需要二次确认的信息和内容再次进行分发识别,结合云端数据对规则进行进一步细化。
云端AI调度部分已经复用于超级APP的云端AI调度中。
事件分级呈现的APP

APP基于事件分级通知和展现逻辑,以信息流的方式对安防事件进行呈现。
APP率先完成了视频云、IoT云的验证,已经复用在超级APP中。
以人脸人形为基础,面向场景深度优化逻辑规则
人脸、人体的关键点检测是基础,目前主流竞品无论B端还是C端场景都是以此为核心,关键问题在于面向场景深度进行逻辑定制和模型优化,大幅提升准确度的同时降低误报率。
通过套用场景逻辑,配合外部传感器,可以将安防场景更加直观,在逻辑之上进行报警也能进一步降低误报。
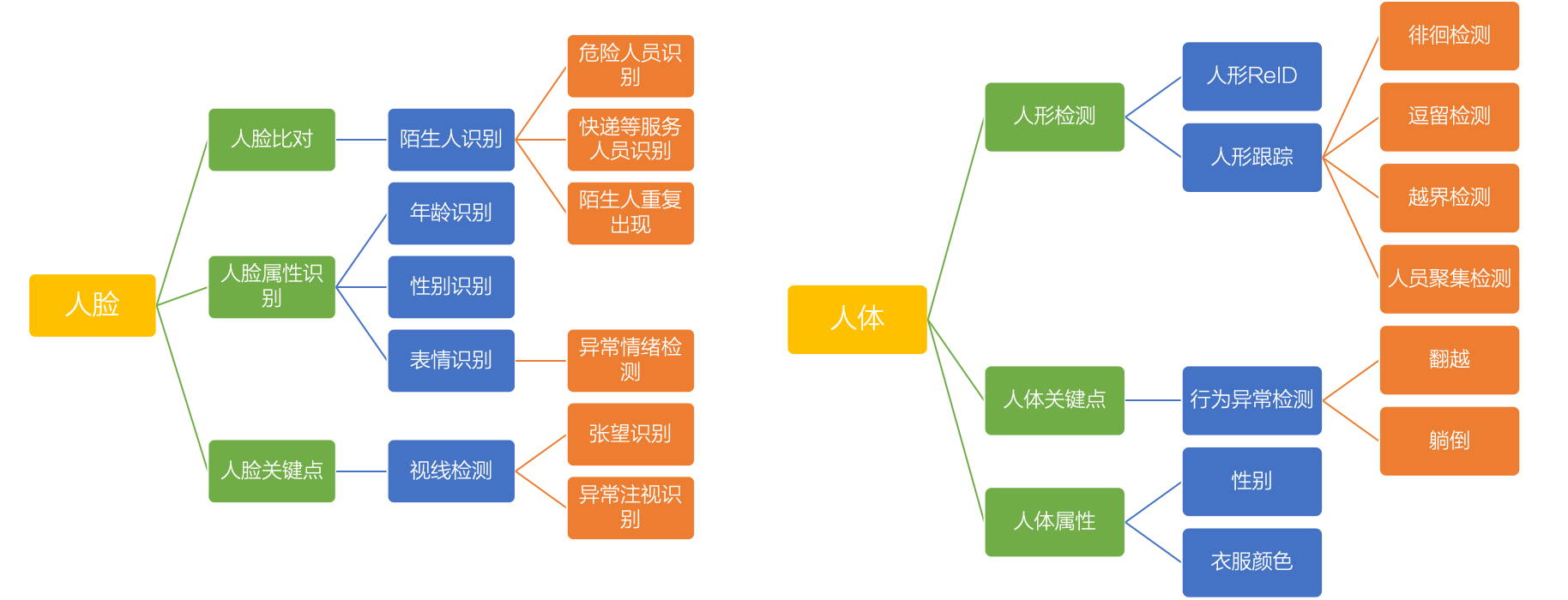
按照事件组合分级提醒,降低误报
在基础的人脸、人形检测,结合传感器关联的基础上,叠加场景逻辑进行事件分级,降低误报
基础的人形人脸检测仍然有误报,通过叠加场景逻辑,如人形检测的基础上,叠加逗留、徘徊判断等场景逻辑,进一步提升准确率,降低干扰。
受到光线等环境影响,传统安防漏报率也比较高,通过和传感器进行关联,撤布防更容易,报警更加直观。
APP的界面呈现同样以消息的分级为主要逻辑,提升重要信息获取效率,降低对干扰
按照事件类型依次划分4个等级,APP的呈现逻辑也以此为基础进行划分。
记录型消息不提醒用户,但是进行存储和逻辑区分,如陌生人出现一次记录,但是重复出现警示提醒。
警示和驱离消息简单直接,能够直接提取有用信息。

结合AI的相对优秀的交互体验
家庭安全大脑在事件分级的基础上,将非线性的AI报警事件和线性的时间轴做了很好的融合,同时画面中会实时显示AI分析检测结果,创造了非常好的应用交互,用户体验与AI感知明显。

针对一些家庭AI场景也做了前期探索

在未发布的NAS产品上做了进一步的探索
除了视频的AI结构化分析之外,在未发布的NAS产品上,也基于AI做了进一步的探索,研发了AI场景识别、照片智能聚类、智能推荐等功能。


当前节点的关键是打造效率平台支撑AI迭代

打造一套通用的场景化视频AI落地效率平台,数据能够半自动化的标注,模型能够高效率的训练迭代,在一套硬件上,能够根据场景选择自动加载场景规则和AI算法,成为专用的场景化硬件。
场景规则:一套固件灵活适配不同场景

场景规则引擎的核心是将与场景相关的规则以及对应的软硬件调用,充分抽象,动态下发、动态执行,同时能够方便的客制化
输入项:视频流、声音流、PIR、按键等硬件输入,物模型调用输入,夜视切换、画面异动、声音异响等输入;
输出项:事件上报、声光、云台控制;
调用项:抽帧逻辑、图像预处理逻辑、AI模型调用。
基于解释型语言构建嵌入式场景规则引擎
一定是解释型语言,脚本可以动态生成、动态下发;
和嵌入式的C语言可以方便的互相调用;
足够轻量级,Linux系统、RTOS系统甚至逻辑都可以使用;
尽量减少性能损耗。
基于Lua语言构建场景规则引擎
和Python等一样,都是脚本语言;
C语言开发,极其轻量,编译后仅100K左右;
方便被嵌入式程序调用,调用简单,对环境依赖弱;
性能损耗低,运行性能能够达到Micro Python 近20倍。
通过构建场景规则引擎,运行能够动态加载、动态执行的脚本预研,实现将场景规则逻辑、AI调用、事件上报等完全抽象,能够在一套硬件、一套固件上,实现对不同场景的规则化匹配,这是场景定义摄像机的前提!
场景规则:基于Blockly封装场景定制化
 Blockly是由谷歌推出的,一款基于Web的、开源的程序编辑器
Blockly是由谷歌推出的,一款基于Web的、开源的程序编辑器
直接支持 JavaScript、Python、PHP、Lua、Dart 语言源码的导出;
基于Web开发,可以直接集成到Web中,使用简单,也可以方便的集成到Android和iOS中;
和Scrach在交互上高度类似,在语言支持上更丰富,
可以做深度二次封装。
基于Blockly做场景定制,不是让用户在手机上做编程,而是利用模块化代码拼接生成功能,将原来固化的场景设置规则化,封装后可以是和原来一致的简单交互,也可以拓展出更个性化的细分设置。
算法由规则调用,按需加载,组成成场景功能

云端AI分发:端云融合、自研三方兼容
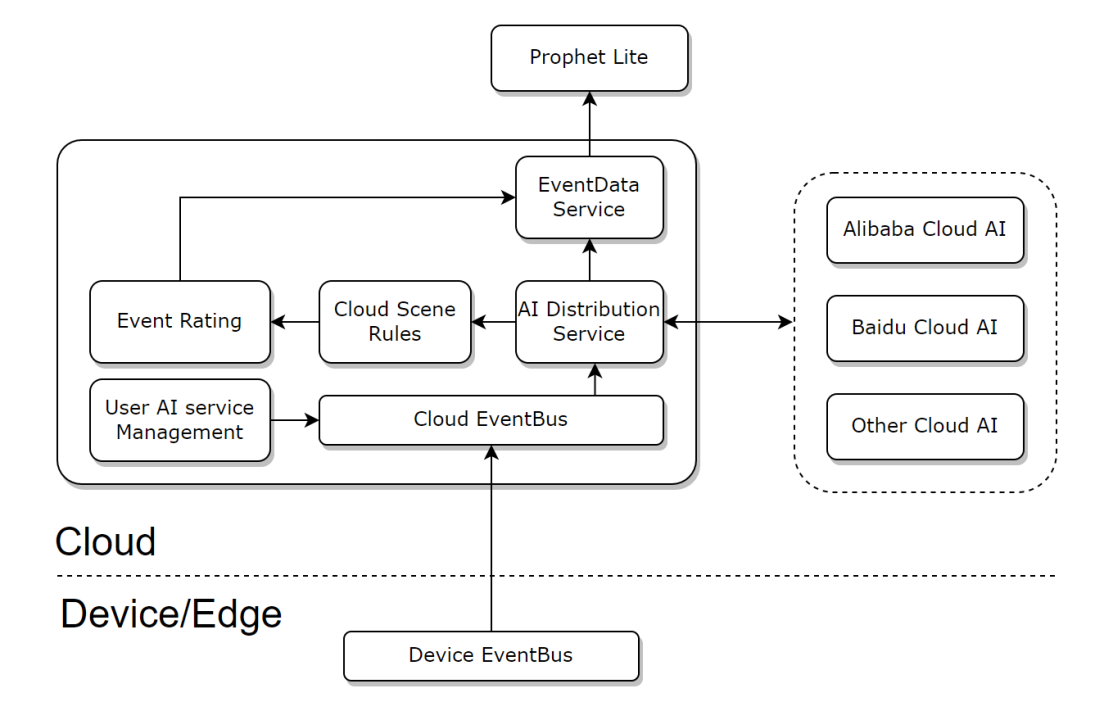 核心需求和目的
核心需求和目的
长尾的AI能力自己不折腾,通过统一的平台接口分发调度第三方,一次对接,多功能接入;
不同场景的AI识别物模型基于此平台做转换归一;
核心的人脸、人形自研,调度自己的服务,但是可以数据抽样调度第三方来做数据交叉验证;
可以做数据的半自动化标注,提升数据标注效率;
小安智能平台已经完成
新老平台设备可以直接拉流、抽帧;
云端的抽帧逻辑、画面区域等规则处理;
对接了公司内外多个平台,众多AI能力可以直接调用;
对接了公司的AI能力定制平台。
无论B端C端,云端的规则、AI分发,未来的数据标注和模型在线训练等基于小安平台合作开发,复用小安已经实现的后台逻辑,和端侧的规则相匹配。
APP端侧AI:打造更智能的交互体验
阶段一:基于手机端AI算力,提升交互体验
利用手机CPU的AI算力,在开流、回放等场景中,实时检测人脸人形检测、跟踪,实现人脸、人形的动态放大、跟踪;
能力和播放器深度整合,成为超级APP的标配功能,和端侧算力互补,端侧没有人脸、人形识别数据时,可以自动切换手机端检测。
阶段二:APP对预加载的事件视频进行计算、结果回写
APP打开查看相应的视频时,对查看视频和预加载的视频,并进行抽帧识别,将识别到的结果继续上云,回写事件数据库,更新结果;
一次查看后,下次查看更新为识别后的结果,一人查看后,其他人查看更新后的结果,提升使用体验。
打造支点型的爆品
结合半导体行业算力平民化的大趋势,相信在当前芯片短缺后很快会迎来算力上的内卷,第一时间积极甚至激进的推进主力产品的AI化,基于AI LAB推出算法商店,推动摄像机向着可以安装场景化AI应用的真智能摄像机转型。
除了C端之外,结合SaaS边缘智能计算硬件,打造承载AI落地的场景化AI平台,推出软硬件一体的解决方案。

评论