
家庭安防的智能化进一步发展,必然是多模态大模型下沉到边缘端,支持在本地做推理,解决云端推理的成本和实时性问题。
去年年底,包括360、安克等在内的一众厂商都在寻找边侧大模型的芯片方案,我也拜访了算能、爱芯元智、无问芯穷、ARM中国等一堆芯片厂商,对比了十来款芯片产品,然而直到今天,性价比最高的边缘计算产品,仍然是M4的Mac Mini。
16G内存显存一体化设计,8B甚至14B的模型能跑;
算力优秀,38TOPS左右的INT8算力,但是显存大,价格便宜;
国补3000以内的价格真的可以,苹果性价比最高产品。
为了测试边缘场景大模型结合安防能玩出什么花来,搭建了一个家庭的测试场景看下效果。
场景需求
家里俩娃经常调皮、干架,周末在家一天能吼好多次,于是乎就像能不能不让我来干预,大模型分析他们的行为,联动客厅的小爱音箱自动提醒。
需求:
儿童危险行为识别与干预
实现方式:
之前调用云端GPT-4o一个星期消耗了4千块的费用,实在扛不住,改为边缘端大模型测试。
边缘端的多模态大模型连续识别画面内容,大模型分析有风险时联动音箱提醒。
架构设计
基于低代码平台Node-Red搭建工作流,整体的实现非常简单,工作流比较清晰,概述为:
360双摄云台摄像机RTSP流→
视频流接入群晖Sruveillance监控套件→
监控套件配置事件检测触发Webhook回调→
调用到Node-red中,获取图片,转Base64,构造请求调用局域网M4 Mac Mini上的多模态大模型→
判断结果,有异常调用HomeAssistant中的小爱音箱播报服务实现音箱实时播报提醒。

1、使用360的双摄云台摄像机,两个镜头支持独立的RTSP流,视频流接入群晖Surveillance监控套件,设置画面变化触发,通过群晖中的webhook回调Node-red中的http-in节点。
群晖配置如下:
细节不在赘述,摄像机接入后,在事件通知中勾选勾选动作检测、入侵检测的webhook通知,webhook中填写node-red中的URL地址,且在参数中把截图地址传过去,方便Node-red直接获取画面截图。

2、通过webhook调用到Node-Red中,通过fuction节点调用局域网跑在MAC上的大模型。
Node-Red中的http-in节点接收回调,收到调用后,从调用的数据中解析出事件截图的地址,截图直接通过http节点请求获取图片,使用image-tools工具转换成为base64和后续预览。
按照LM Studio的调用方式构造调用函数,组合Prompt与图片,调用局域网内Mac Mini上的大模型。
3、Node-red调用HomeAssistant中的小米插件,用于让小爱同学播放TTS。
大模型调用返回结果,根据Prompt要求的格式化输出判断有无异常,无异常忽略,有异常调用HomeAssistant中的小爱同学播放TTS。
模型选择与测试
考虑到边缘端在16G内存的Mac Mini上运行,选择14B以下的模型,结合开源的多模态模型榜单,选用Shanghai AI Laboratory开发的InterVL3-8B,模型信息如下。
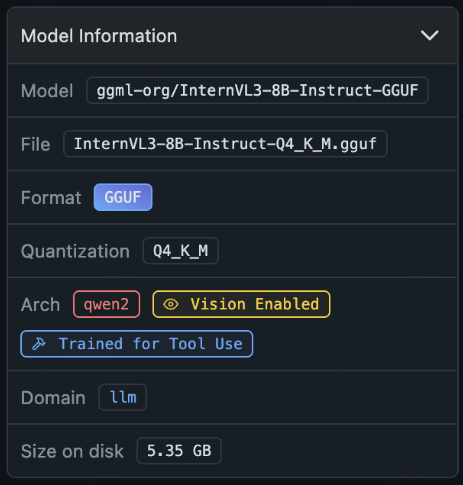
通过LM Studio在Mac上搭建局域网的大模型调用服务。

先做下测试,看看速度。
Prompt如下:
# 任务
分析上传的监控图片,快速识别儿童可能面临的安全风险,并提供简短明确的安全提示
# 分析要点
1. 高处攀爬(家具、窗台、楼梯等)
2. 接触危险物品(尖锐物、小物件、电器、药品等)
3. 儿童间打架
4. 可能导致跌倒、触电、窒息的行为
5. 无人看管的危险区域活动
# 输出格式
- 危险场景,输出:[简述具体危险行为] + [安全指令]
例:"攀爬危险!赶快给我下来!"
例:"剪刀危险!赶快放下不要乱拿!"
例:"不要打架,赶快停手!"
- 安全场景只需输出"无异常"
# 要求
1. 使用日常口语,不能包含任何专业术语;
2. 最终输出必须控制在20个字以内;
3. 符合多个场景时只输出危险程度最高的一个场景;
4. 回复内容严格按照格式,不添加任何解释或额外内容。图片没压缩,用的2560*1440的摄像机图片。速度还可以,首Token接近5秒,速度20Token/s,勉强可用。
其他备选模型
结合多模态模型榜单,后续更换其他几个模型也做下对比测试。
Qwen2.5-VL-7B
Ovis2-8B
测试效果
整体测试效果满足预期,画面变化触发大模型识别,有结果立刻音箱播报,从测试角度符合预期,但是从实用角度差距很大。
主要问题
模型的指令遵循和一致性问题
模型参数量级较小,提示词的指令遵循能力一般,如不按照要求输出内容太多,或者经常输出非口语化的表述。
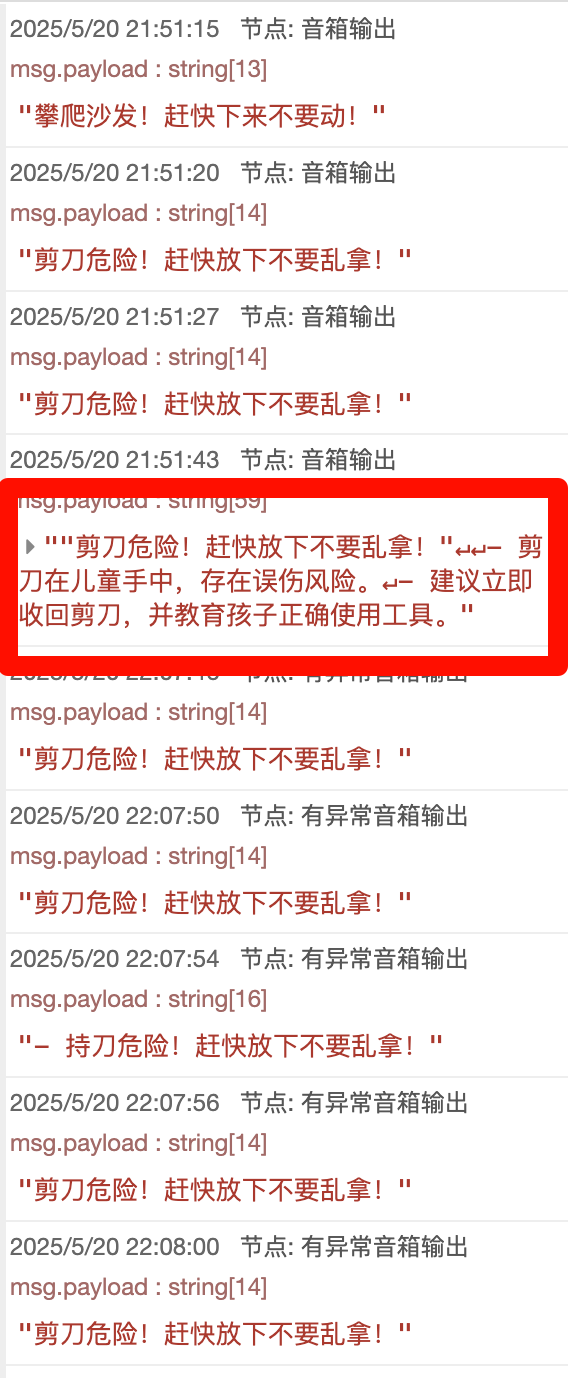
场景理解一致性的问题
Prompt中列举了希望检测的危险行为,如打架、爬高,手拿尖锐物品等,实际测试经常出现玩具散落一地,播报有绊倒风险等,在风险的定义和预期上差异较大,反复调整Prompt效果会有震荡,没有完全达到预期。

特殊场景的识别问题
如夜间的夜视场景,大模型识别结果经常出现异常,关灯了触发画面变化调用大模型,大模型播报有风险。
评论