
多模态大模型发展回顾
2023年5月31日360在国内率先发布了视觉大模型,并探索了在安防场景的落地应用。作为项目负责人,之前花了很大经历,对核心的技术路线、里程碑项目做了一个梳理,核心的资料来源还是基于CVPR上的上百篇论文,在一个月的时间内每天晚上两三篇,建立了对视觉及多模态大模型的基础认知和理解,本文从产品经理视角,简明扼要的做一个分享。
主要关注什么?

在具体的应用领域,主要关注三部分:

主要关注哪些项目?
以下项目是我梳理的与视觉及多模态大模型相关的核心项目。
核心项目介绍
CLIP连接图像和文本,多模态预训练模型的开山之作
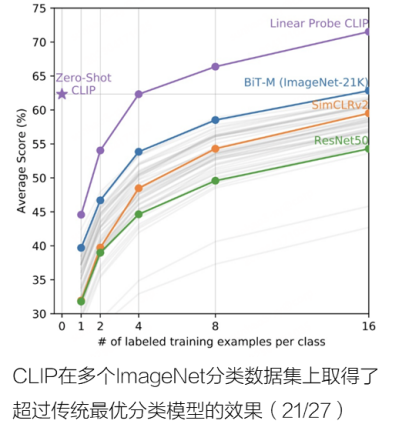
Open AI 2021年1月发布的视觉模型,利用网络的4亿图像、文本对进行自监督综合训练,本质就是将分类任务化成了图文匹配任务,效果可与全监督方法相当。在近 30 个数据集上 zero-shot 达到或超越主流监督学习性能。

BLIP2下一代多模态模型的雏形
ALBEF、BLIP、BLIP2都由Saleforce亚洲研究院发布,BLIP2充分利用已有的图像预训练模型和LLM,将多模态特征Q-Former中进行融合,最后送入LLM模型,提升了模型的图像理解与推理能力。


BLIP2在图片问答VQA、图片生成描述Caption、图文检索等测试项目中,取得了较好的表现。
BLIP2增强了多模态大模型的图像理解与推理能力
信息检索与背景知识能力
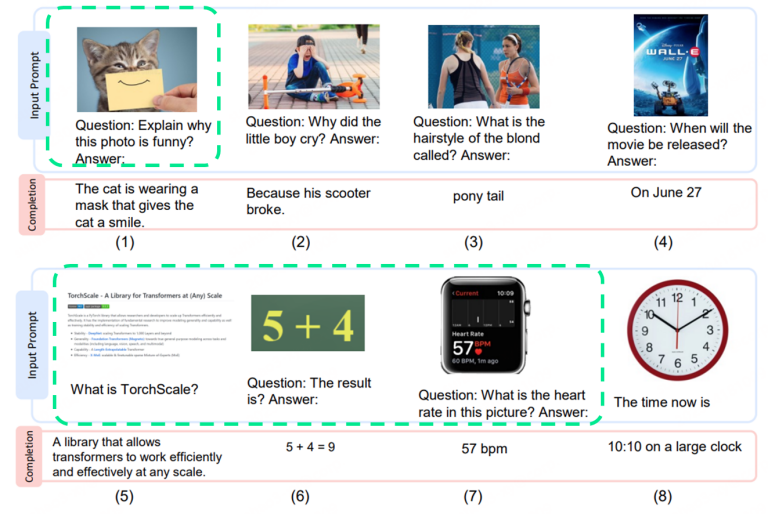
对图片中物体的背景知识提问,可以看到,模型都给出了相应的答案。这里体现的实际上是LLM强大的背景知识库。图中有什么(ViT)+ 问的是什么(Q-Former,LLM)+ 找答案 (LLM)
内容理解与推理能力
能够识别图片内容,并建立内容之间的逻辑关系推理,如图一中,知道房子,知道看起来倒过来了,能认识滑梯。图二中,知道男人害怕是因为鸡飞向他。
场景理解与生成能力
能够理解场景,并结合场景内容做关联输入,基于大语言模型做文本生成,如图三,基于狗背上的猫,模拟生成一段对话。

Kosmos-1多模态大模型走向“真正统一”
Kosmos-1是微软在发布的一个多模态大语言模型,主干是一个基于 Transformer 的语言模型。将视觉、语音等其他模态也嵌入并输入到该模型中。核心目的如论文标题:Language Is Not All You Need: Aligning Perception with Language Models模型、算法并未开源,实现细节也并未描述太多,横向对比也不充分。


Kosmos-1在图片问答VQA、图片生成描述Caption、图文检索等测试项目中,取得了目前最好的表现(未对比BLIP2)。
Kosmos-1展现了更强的VQA场景
更深的图像理解能力
如能够看懂第一张图片中好笑的点,能够理解图片深层的含义,和GPT-4展示的多模态理解能力类似。
融合OCR的信息
能够识别图片中的文字信息,将OCR识别信息综合进行语义理解。能够执行内容提取、数学运算等进一步的操作。
Meta SAM分割大模型,CV领域的GPT-3
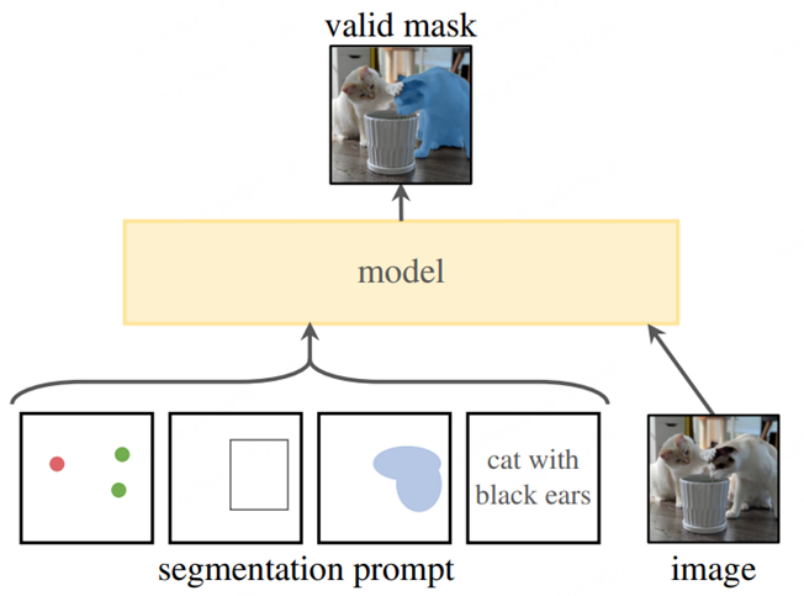
2023年4月5日,Meta 开源了分割模型Segment Anything Model (SAM) 以及对应的1100万张,11亿Mask的分割数据集。“SAM 已经学会了关于物体的一般概念,并且它可以为任何图像或视频中的任何物体生成 mask,甚至包括在训练过程中没有遇到过的物体和图像类型。SAM 足够通用,可以涵盖广泛的用例,并且可以在新的图像上即开即用,无需额外的训练。”
SAM初步验证了多模态技术路径及其泛化能力,被认为是CV领域的GPT-3。

高效灵活的设计带来交互体验的巨大提升
模型分为一次性图像编码器和轻量级的掩码解码器,解码器在浏览器中可以毫秒级运行。
DINOv2融合了目标检测、深度估计、语义分割
DINOv2: Learning Robust Visual Features without Supervision
4月14日Meta发布并开源了DINOv2模型,不同于SAM单一的分割模型,同时支持目标检测、深度估计、语义分割等多种任务,并在图像的自监督训练上取得突破。
DINOv2创新和优秀性能在于用自监督学习方式训练
以CLIP为代表的许多视觉模型使用图像和文本配对数据做预训练,Meta 认为该方法依赖于文本描述图像的语义内容,因此会忽略文本描述中通常未明确提及的重要信息。例如,在一个巨大的房间里有一张椅子的图片的标题可能是“一个椅子”,而错过了背景信息,如椅子在房间的空间位置。DINOv2 是基于自监督学习的,训练数据是Meta 构建的大型、精选且多样化的数据集,通过从约25 个第三方数据集中先设置一组种子图像,然后寻找和这些种子图像的编码距离接近的图像进行聚类匹配,在12 亿张源图像中生成了总计1.42 亿张图像的训练数据集。虽然图像没有文字标注,但模型可以通过图像之间的关联来学到图像特征,克服了文本对图像描述不够全面的局限性

SEEM卷出图像分割新高度
虽然 SAM 推进了 CV 大模型的进展,但其分割结果缺乏语义意义,提示类型也仅限于点、框和文本。很快微软来自威斯康星大学麦迪逊分校、微软、香港科技大学的几位华人提出了SEEM ,SEEM能够根据用户给出的各种模态的输入(包括文本、图像、涂鸦等等),一次性分割图像或视频中的所有内容,并识别出物体类别。在多模态交互层面卷出了新高度!


模型组合实现更多任务:Grounded-SAM、SSA
4月8日由复旦大学发布,利用CLIP和BLIP生成语义标注,与SAM的分割结果相结合,生成泛化能力更强语义分割模型。
是第一个利用SAM进行语义分割任务的开放框架。它支持用户将其现有的语义分割器与SAM无缝集成,而无需重新训练或微调SAM的权重,使他们能够实现更好的泛化和更精确的Mask边界。


扩展到特定区域和视频场景:Caption Anything,Track Anything

4月11日由南方科技大学和腾讯ARC Lab开源了一款交互式图像描述工具, 基于Segment Anything, BLIP-2 Captioning和chatGPT实现, 通过视觉控制(鼠标点击)获取特定区域的object, 并以多样化的语言风格描述出来。
4月14日由南方科技大学开源的一款视频目标追踪(VOT)与视频图像分割(VOS)工具,TAM将SAM 和XMem (VOS模型)结合在一起,并以交互方式整合它们。首先,用户可以交互式初始化SAM,即点击目标对象,以定义目标对象;然后,根据时间和空间的对应关系,使用XMem在下一帧中对目标对象进行掩码预测;接下来,使用SAM提供更精确的掩码描述;在跟踪过程中,如果发现跟踪失败,用户可以暂停并进行更正。
视觉模型连接融合大语言模型:Mini-GPT4、LLaVA
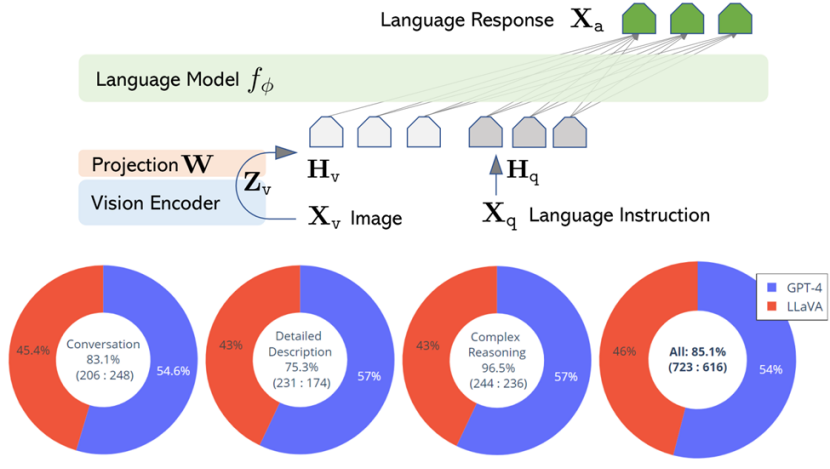
Mini-GPT4在核心算法上并无突破性创新。团队认为GPT-4的先进的多模态能力,主要是利用了更先进的大型语言模型,因此团队将BLIP-2与大语言模型Vicuna(小羊驼)进行对齐、融合,通过模型微调,先用500万个文本-图像数据训练,然后再用3500个高质量的数据微调,语言模型有了理解图像的能力。

LLaVA使用ChatGPT/GPT-4将图像-文本对转换为适当的指令跟随格式。将CLIP视觉编码器与大语言模型Vicuna连接起来,并进行端到端微调。与MiniGPT-4不同的是,LLaVa主要是把instruction-tuning放到了多模态模型上,这是将指令调整扩展到多模态空间的第一次尝试。
在VQA测试中,达到GPT-4 85%的能力。
以ChatGPT为中枢,调用多模型:Visual ChatGPT、HuggingGPT
3月9日微软亚洲研究院发布Visual ChatGPT,4月3日,再次联合浙大,发布HuggingGPT,将前者调用的视觉模型进一步扩展到社区中所有的开源模型。核心思路是以ChatGPT作为自然语言处理中枢,理解用户输入需求,整合调用其他专业AI模型实现多模态的输入输出。
1. 任务规划。将用户的需求解析为任务列表,并确定任务之间的执行顺序和资源依赖关系。
2. 模型选择。根据HuggingFace上托管的各专家模型的描述,为任务分配合适的模型。
3. 任务执行。混合端点上被选定的专家模型根据任务顺序和依赖关系执行分配的任务,并将执行信息和结果给到ChatGPT。
4. 输出结果。由ChatGPT总结各模型的执行过程日志和推理结果,给出最终的输出。


啥结论?
2023年的上半年是视觉及多模态大模型研究爆发式增长的一年,既有SAM这种纯视觉的重量级成果,也有Mini-GPT4、LLaVA这样的短平快缝合路线取得了很好的效果,给视觉大模型的落地提供了很好的落地指引。最终360视觉大模型一期借鉴了Mini-GPT4和LLaVA的思路,原生多模态融合和单模态专家系统缝合并行,优先结合安防场景同步做落地探索。关于更细节的路线选择和落地分析在后续的文章另行探讨。
评论