
读论文:Chameleon: Mixed-Modal Early-Fusion FoundationModels
论文地址:https://arxiv.org/pdf/2405.09818
先用360 AI浏览器对论文做下总结。以下由AI阅读生成。
AI阅读
以下由360 AI浏览器生成。
主要观点
Chameleon模型介绍
Chameleon是一个混合模式的早期融合模型,可以处理图像和文本的任意序列。
模型从构思到训练方法、对齐策略和架构参数化都专门为其设计。
Chameleon的架构创新
使用全令牌表示法处理图像和文本模态,通过量化图像为离散令牌,可在不使用单独编码器或解码器的情况下应用Transformer架构。
训练稳定性和可扩展性
提出了新颖的变压器架构修改和训练技术,如查询-键标准化和修订的层规范位置,以实现混合模式下的稳定训练。
广泛的评估
Chameleon在视觉问题回答、图像描述等多种任务上表现出色,同时保持了与其他大型模型在纯文本任务上的竞争力。
人类评估
进行了大规模的人类评估,显示Chameleon在开放式混合模式推理和生成方面具有独特能力。
总结
Chameleon代表了向统一建模全多媒体文档的重大进展,它不仅能够处理和生成混合序列的文本和图像内容,而且通过稳定的训练方法和架构创新,成功实现了这一目标。模型在广泛的任务中展示了最先进的性能,尤其是混合模式的长期生成能力,这标志着混合模式基础模型的新高度。
我的观点
以下为个人观点,手工输入。
端到端多模态的里程碑
之前的多模态大模型,以LLaVA和mini-GPT4为代表的,包括我发布的视觉大模型,本质上走的都是单模态专家缝合路线。理论上,这种路线的天花板很低,但是奈何落地快,对算力等要求较低,在一些垂直场景使用,应该还碰不到这个很低的天花板。
典型项目可以参考:多模态大模型发展回顾-核心项目总结分析
Meta作为开源的急先锋,以LLama系列为代表的开源模型,直接决定整个大模型开源领域的技术水平,在当今端到端多模态都为闭源的情况下,这个模型如果能够像以往的模型一样开源,确实是一个大的里程碑。
端到端混合与单模态专家缝合
在以往的多模态基础模型(包括Flamingo 、LLaVA和VisualGPT等基于后融合的模型)中,多数使用模态特定的编码器或解码器,将文本和图像等模态分别输入。然后通过特殊的结构设计将不同模态进行对齐缝合,这种对齐仍然会导致不同模态在映射上有一定损失,而且并没有实现真正的多模态融合。
而Chameleon一开始就是一个混合模型,并以端到端的方式在混合模态(包括图像、文本和代码)输入上进行训练。
Chameleon等使用的前融合方法在输入时就将所有模态映射到共享的表征空间中,方便跨模态的无缝Inference和生成。为了解决优化稳定性和Scaling的问题,Chameleon做了架构和训练方法的创新。Chameleon团队对ransformer 架构进行了修改,包括Query-Key归一化(normalization)和Layer Norm位置的修改。这些调整对于混合模态的稳定训练非常重要)。

作为对比之前的LLaVa等模型实现,仍然是独立的编码融合方式。

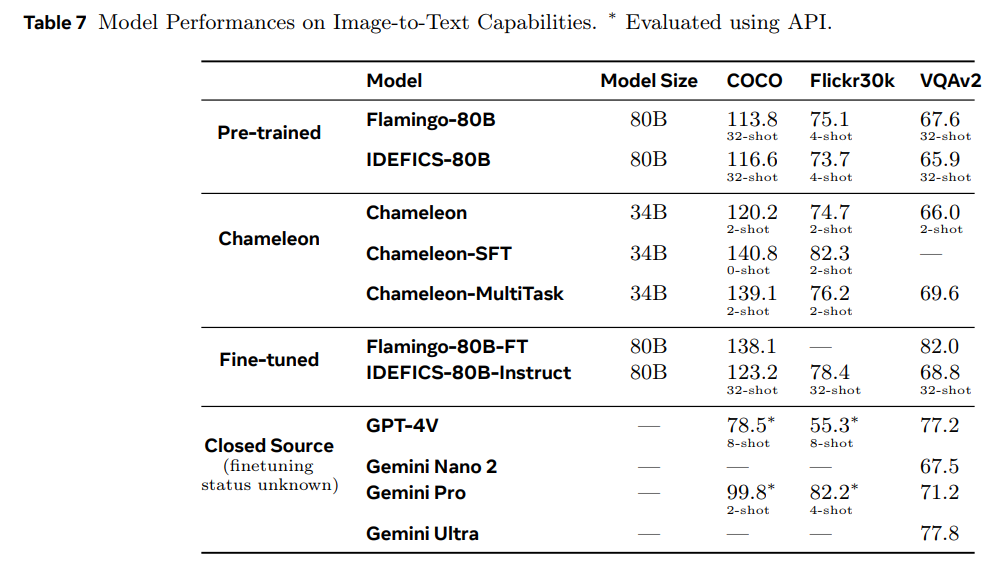
具体的方法不太懂,也没有细研究,看了下跑分情况,论文中并没有和LLAVA这类缝合多模态做对比,和GPT4V对比,在图生文任务上较小的模型却有着突出的表现。
最后期待,早日开源。
评论