
2024年7月27日,第三届超声波俱乐部AI Open Day“2024垂直引爆:AI教育引领AI应用大爆发”在北京360总部成功举办。本次峰会聚焦AI教育领域,二百余名教育与AI领域的创始人,投资人,知名教育集团的创始人、CTO、AI负责人等现场出席。
360智慧生活集团副总裁孙浩进行了一场精彩的分享,以下为孙浩的分享整理:

分享嘉宾:孙浩,360智慧生活集团副总裁
分享主题:大模型重新定义儿童手表
7月8日,我们发布了全球首款搭载大模型的儿童手表——360儿童手表A9 AI红衣版。发布会后,我对怎样看待新技术、新产品,以及对外的公众表达方面,有了很多新的感悟。今天来的都是行业内的朋友,我想把一些偏技术和产品的内容以及背后的故事稍微展开讲讲。
从卷基础模型,到卷场景
周总之前做过预测,2023年是基础大模型突飞猛进的一年。去年大家都在卷大模型,我们的一个工作重点是做多模态的视觉大模型,并发布了360的视觉大模型,战略聚焦也更多的是在安防上。

多年来,我一直围绕硬件和AI的结合进行探索,手表是其中一个场景。总的来说,这些年做产品属于越做越自闭的类型,尤其硬件这两年在创投圈比较冷淡,而大模型已经千模大战、万模大战。做大模型的门槛非常低,尤其是以LLama为代表的大模型开源后,出现了一堆大模型及Agent的创业公司。

接着,很多公司进行了大模型+智能硬件的尝试,但每个硬件都有自身的定位,在没有达到对应的技术或场景积累的时候,不要硬拔它。做一个硬件就能够彻底颠覆某一个品类的预期太高了,但换到很多垂直场景里可能会完全不一样。把现有的能力增强以后,一样能够取得非常好的效果。
手表是儿童场景最佳的大模型硬件载体
当然,我们也在反思两个问题。第一,大模型需要什么硬件?第二,我们是否又盲目地说做了一个革命性的智能硬件?世界上这种革命性的机会一定有,但往往是极其稀缺的,不可能随便做一个就能颠覆一个产业,更多的还是要找准这个场景的真实需求,把这个场景限定好,把这个场景里面限定的功能做齐,再有了大模型这样一个强有力的工具之后,能切实解决一些问题,这才是合理的。
现阶段无论是是从儿童手表这个硬件载体的特点还是从儿童使用的这个群体本身,手表都是儿童场景最佳的大模型硬件载体!

AI是不是会取代人类?我们认为,在整个大模型技术不可逆转的今天,更明确的观点是:会使用AI工具的人会取代不会使用的人。所以,如果00后是互联网原住民,那么现在的孩子就是大模型的原住民。


这也带来了新的焦虑:未来大模型技术不断发展的情况下,这批原住民真正步入社会的时候,给他们的空间还有哪些?我们希望手表能作为一个切入点,让孩子在和大模型的交互过程中,学会探索世界并激发好奇心。
为了做好产品,我们一直考虑的是,如何在孩子的成长过程中将技术有温度地结合,给孩子打造一个强大有耐心的AI伙伴,能够伴随他成长,引导他持续地学习向上。

儿童手表进入大模型时代
从2014年360在行业内首创儿童手表这一新品类开始,我们的核心定位逐渐从安全转到沟通,直至今天进入大模型时代。

2015年,我接到了做一款革命性的儿童手表的任务,当时无知者无畏,对儿童手表的基本认知是:这是孩子唯一的通讯设备,本质上是孩子的小手机。但那时候很多儿童手表的产品都做了一个低龄化的外观,比如有对小耳朵,甚至连正常的屏幕都没有。大家会天然从成年人的视角出发,觉得小孩就应该用一个非常低幼的卡通化的东西。
可调研发现并非如此,7岁是孩子很重要的时间节点,孩子7岁以前独立意识很弱,7岁以后独立意识增强。我们认为反正都是孩子,但实际上有很多细分在。我当时的认知就是儿童手表需要在一定程度上成人化,起码在硬件配置和形态上需要成人化。现在来看,那时的认知是成立的。
2016年做这款手表的时候当然没有普通手表那么成人化的外观,但功能已经相对多样化了,其中第一个核心的功能就是语音交互。因为我们判断儿童手表上如果出现杀手级的应用,那第一个肯定是语音交互类的应用。当时我们面临的挑战是怎样把语音交互面向孩子的场景做好。
虽然当时很多语音助手呈现出来的是科技感,但我第一天做儿童手表上语音交互功能的时候,拒绝给用户呈现任何生硬的科技感。手表上屏幕一滑,跳出来的是一只可爱的宠物形象,叫巴迪龙——这个形象一直保留到现在。巴迪龙会吃饭、跑步,还可以升级等等,我们给它运营了很多有趣的动作。

受限于传统的语音处理技术,我们遇到了非常多的挑战。比如做一些兜底回答的时候,我们最常见的兜底回答是:“抱歉这个问题我不会,你可以问一下你的爸爸妈妈。”但如果总是给孩子说这个,孩子会感觉很无趣。所以我们也做了一些新的尝试,比如“哼,你今天的话怎么这么多,你是个话痨吗?”这种方式反而更能激发孩子的沟通欲望。
后台的数据显示,和巴迪龙的互动已经是用户最常用的功能了,而不是打电话或者给妈妈发消息。78%的用户每天会用巴迪龙、跟巴迪龙对话。平均每天能到20轮以上,15分钟以上;周末节假日能到30轮以上,30分钟以上。从发布到现在我们服务端已经超过了50亿次的调用,那么多年来即使没有大模型我们也一直在做这个事情。

另外,我们做了很多小功能,比如巴迪龙不会的部分会在家长端生成问题记录,我们的预期是家长能够知道孩子对什么信息好奇,然后在跟孩子沟通的时候告诉他。
其中有一个案例令我印象深刻。一位单身父亲曾向我们发了一个巴迪龙不会的问题记录截图:爸爸妈妈离婚了我该怎么办?原来这个父亲认为,给孩子买最好的东西,让孩子用到最新最酷的数码设备就是对孩子好,但是实际上缺失了对孩子内心的关怀。此事对他产生了触动和反思,我也第一次察觉到这一功能背后蕴藏的温度。
后来,为了使巴迪龙更具个性化,我们尝试做了一些生成式的聊天算法,但也踩了许多坑。首先由于技术局限,我们只能精准地去找一些问答去做训练,比如论坛里的对话,但要花很大力气去清洗数据。清洗完后,发现生成的内容还是不可控,于是我们又做了一些限制性的问答,同样花费大量人力,清洗出一个干净的语料库后再做训练。结果这样下来,整个聊天会变得很无趣。我们不断地在尺度和安全性之间反复徘徊,所以当时做到最后,我们还是去掉了生成式闲聊这个功能。
但是,孩子本身说话经常没有逻辑性,他们的很多问题也是偏娱乐性的,对答案的预期要求没那么高,所以生成式闲聊功能一直以来也深受孩子的欢迎。

大模型技术给儿童语音问答带来质的飞跃
去年大模型火了之后,我们发现机会来了。但问题也随之而来,核心是幻觉问题,如果没有检索增强或图谱类的技术,这种幻觉问题会持续存在。比如我们之前用的SR技术,都是三段式的,先要SR转文本。这样就很受局限,哪怕你的知识库匹配的是对的,但它前头的ISR识别不出来你也没办法。但今天,大模型有很好的输入的冗余能力,即使它输错了,一样能够很好地去理解回答,有了很大提升。
另外,现在大模型的上下文窗口对于一个聊天应用来说,也足够把上下文串起来了。以前没办法真正做到跨场景的多轮聊天,但孩子跟它聊15到20轮的时候,它也能够串起来,之前一直困扰我们的聊天功能终于实现了质的飞跃。

但我们仍然很慎重,担心幻觉问题的出现,比如大模型可能会说“风吹草低见牛羊”是杜甫写的。于是我们没有着急抢概念,而是认认真真做了八九个月的时间、慎重地做一些探索。

我们目前的儿童手表,严格来说有一个系统级的入口,这个入口还是巴迪龙。孩子有一个伙伴的形象,就会愿意去跟它沟通交互。
巴迪龙有它自己的人格,背后是统一的基座大模型360智脑。因为是内部团队,合作起来比较顺畅,整体还是基于智脑来做。后面我们也会渐渐开放,并不要求一定是智脑,我们基于智脑做好意图的分发。如果有一些比较好的三方场景应用,我们分发也会用外部的大模型,并不完全局限在智脑,但作为一个基座大模型串起所有功能。
因为你上了云助手,传统的通过语义处理的实现或订闹钟、查天气,一些本地的功能操作还是要在的,包括一些细分场景,写作文这些东西,调不同的功能,所以说也有一套针对手表上的专用的Agent。
最后,为使聊天功能有组织有逻辑地呈现,并突出显性卖点, 我们包装了9个场景,有类似于英语老师、语音老师,孙悟空、爱因斯坦这样一些角色的形象呈现。我们通过预设的prompt和一些数据的微调对齐,尝试做了一些孩子的核心场景。

我们给手表的定义就是一个随身携带、偶尔问一句的伙伴,它并不是一个老师,而是一个助手。随身陪伴、随身携带是它最大的优势。
我们的基本思路不是说在手表上装一个360智脑的APP,而是通过底层的技术做一个AI-Native的实现,围绕孩子的生活学习场景,把语言模型、视觉模型结合好,揉到一个场景里,解决孩子的一些问题。

例如爱因斯坦的相对论怎么解释给孩子,我们花了很大的精力让它去做总结做抽象,保证把它的字数压下来,可以几句话就把核心的东西说出来,不求全,但求简单,让孩子能听得进去。
其实孩子没有人盯着,很难自觉学习。所以我们的核心还是将一些日常的场景和教育的需求融合起来。比如我们的手表上有多模态大模型,手表可以拍照,拍完照之后它就会把这个照片描述出来,还能生成对应的英语,也可以针对这个照片做一些问答。
孩子在探索的过程中满足好奇心,又顺带学到知识,是我们希望手表扮演的角色。我们发现,很多时候孩子会用手表问作业,但我们始终坚持的一个原则是,给思路要比给答案重要,给素材要比给结果更好。
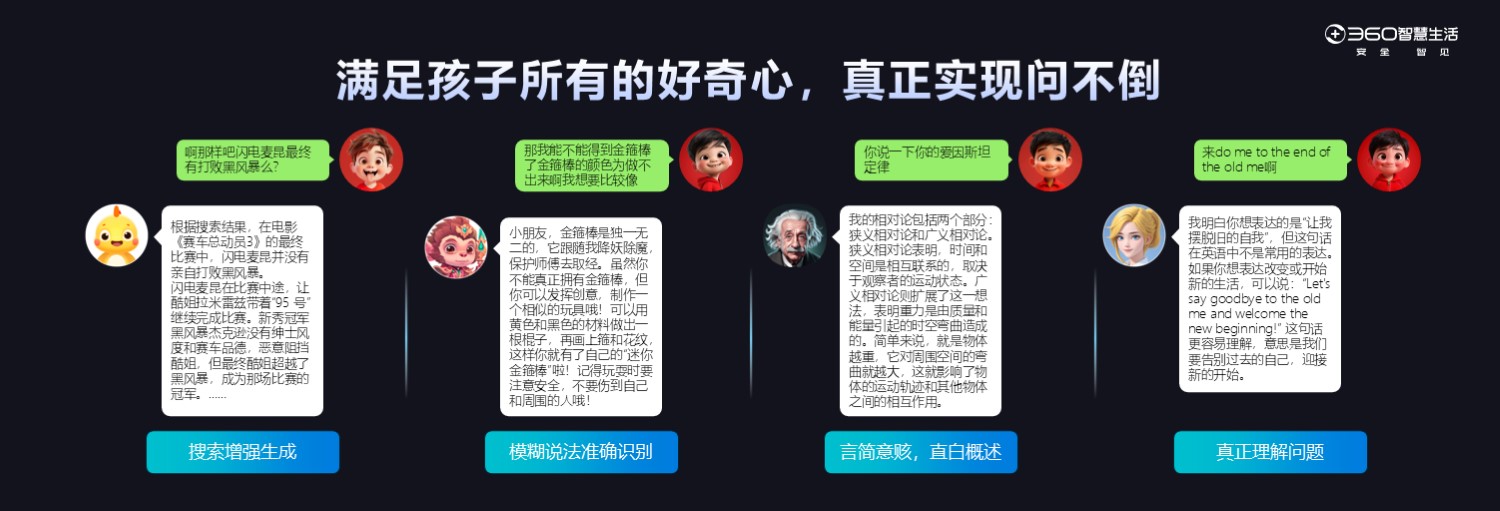
比如孩子问怎么写一个苏州的作文,它会告诉你写作思路,要怎么打头,怎么写中间,怎么结尾,给他几个参考的素材,最后给他一些参考的标题,让孩子自己去组织,可能80%的东西已经给出来了,但它是零散的,孩子在组织的过程中也会自主思考,而不是盲目去抄,这就是我们在教育功能上的思考和体现。

既然孩子没有那么强的自律力,那么我们的思路就是抓住他有限的问问题的机会。但凡他主动问一次,就不要把这次机会浪费了,要举一反三,不断延展给他塞更多的东西进去。因为手表这个形态,本身占用的就是孩子的碎片时间,很难强制孩子对着手表做系统化学习,所以怎样把这些碎片时间利用好,是做这个产品的核心。

视觉大模型能展示出它的认知能力,知道某个图片的笑点在哪里。但在实际生活中,我们很难找到一个人对着图片问问题的场景。我们在安防场景里面应用多模态大模型,有设定好的程序,对每个店铺巡检的图片,自动问问题打分出来。但儿童场景的核心,就是为了满足孩子的好奇心。
如何保持孩子的好奇心不被磨灭呢?是及时正向的反馈。所以,去年我做的多模态视觉大模型就派上了用场,我们把对图像问答的场景放到手表里面,孩子看任何一个东西觉得不理解的或者想知道什么问题,都可以直接拍照。比如孩子去一些名胜古迹,或者看到一些花草,问这是什么的时候,大模型会结合相应的知识告诉他。做这个功能的核心目的,是满足孩子好奇心的场景,这具有非常大的价值。

虽然我们做了大语言模型的问答,也做了多模态视觉的理解,但更成熟的一个技术是AIGC,通过语言文字来生成图像。以Stable Diffusion、Midjourney的文生图工具在过去一年发展迅速,已经广泛地应用到很多创作场景,但是往往需要复杂的提示词,像咒语一样。
现在还有很多人做Agent,去生成Midjourney的咒语。而我们做的,是把科技隐藏起来,所以做了很多后台的工作,都是为了让孩子专注描述他想要的东西。孩子随便说一句话,就能生成图片。我们也在思考怎样引导孩子,一定程度上孩子要发挥想象,然后通过交互来训练和延展自己的想象力。
孩子们追求个性张扬,会把生成的图片用做头像,而成本也远超我们预期,因为他们换头像特别频繁。现在画图的成本是比较高的,后台发现每个孩子平均一天换头像7、8次,这导致我们服务端的成本飙升,原来认为一年的成本可能是40多块,目前最新的数据统计下来,一年服务器成本会到70多块。

安全方面,孩子私下聊的内容涉及到一些危险想法的,或者有安全风险的,我们也在做一些防范行动。我们和一些机构有合作,针对孩子常见的心理问题做了定义,然后用大模型根据对话记录做一些区分和识别。像孩子提到的父母离婚问题,及某些相对危险的点是可以告诉家长的,能够对于孩子有及时的干预和关怀,这是一个前沿性的探索。

文生图方面也是如此,我们以模制模,以大模型来制衡大模型,专门训练了一个图像审查的大模型。手表原来通过定位、沟通等守护物理世界安全,现在通过大模型技术,能够给孩子提供安全的内容交流。

大模型儿童手表能够真正实现听得懂、看得懂、问不倒、讲得清,做到实时响应解决困难和需求,但不能取代家长对孩子的照顾或取代老师,让孩子教育平权,这又拔得太高了。有一个能够随时呼叫出来的小伙伴给他很好地解决困难和需求,这就够了。

一个新的技术一定会带来一个行业革新的机会,但是很多时候一些传统的商业规则必须得遵守。我们说大模型的出现是工业革命,但是工业革命本身是一个很缓慢的过程,不可能寄希望于一个技术,忽视现在一些产品硬件的设计,忽视人家前期的渠道积累和品牌宣传。让用户能够快速认知、快速突破,这个也不现实。
我们一定程度上更多的是把功利心藏起来,就想着这个技术来了,能不能带着敬畏之心踏踏实实地把之前没做好的功能做好,给孩子的成长带来更多的帮助,这才是我们真正在乎的东西。
评论